Using AI for semi-manual SOC 2 evidence collection
Fully automated evidence collection sounds great until you try it. Half the items need human judgment. Here is how a three-phase guided workflow collected 99 evidence items across 4 sessions in 4 days, with AI handling orchestration and a human handling the judgment calls.

If you remember nothing else:
- Fully automated evidence collection sounds great but breaks for half your evidence items
- Semi-manual means AI handles the workflow orchestration while a human handles the judgment calls
- 99 evidence items collected across 4 sessions in 4 days, compared to roughly a week with two people previously
We collected 99 evidence items across 4 AI-assisted sessions. Previous year, this took two people most of a week.
That’s the headline. But the interesting part isn’t the speed improvement. It’s what the AI actually does versus what it doesn’t. Because if you listen to the compliance automation vendors, you’d think evidence collection is a solved problem. Connect your AWS account, link your identity provider, sit back. Done.
It isn’t done. Not even close. At Tallyfy, we run SOC 2 Type 2 every year, and the evidence collection grind is the part nobody prepares you for. Our evidence inventory has 123 items across four different collection frequencies. About 70% of those items respond well to automation. The other 30% need a human to look at something, think about it, and make a call. That split is what makes “semi-manual” the honest description.
I’ve written about the mechanical details of how our evidence sessions work and the organizational busywork that makes evidence collection painful. This post is about why the in-between approach works better than either extreme.
Why full automation doesn’t work for most evidence
The pitch from compliance platforms goes like this: connect your integrations, and the platform pulls evidence automatically. SANS Institute guidance on evidence correctly points out that evidence needs system timestamps, clear source identification, and verified data integrity. What they don’t emphasize is that maybe half of a typical evidence inventory resists full automation entirely.
Screenshots of configuration pages can be automated. Export a user list from an identity provider, sure. Pull a CSV of access logs, no problem. But what about the attestation letter confirming a control doesn’t apply to your organization? That requires someone to evaluate why it doesn’t apply and sign their name. What about verifying that a vendor’s SOC 2 report covers the right scope? You have to read the report. What about confirming that a physical security control exists? No API call answers that.
The AICPA’s Trust Services Criteria framework defines what auditors evaluate, but it doesn’t prescribe evidence formats. Auditors want proof that controls operated effectively during the audit period. Some of that proof is mechanical. Much of it requires judgment about whether the evidence actually demonstrates what it claims to demonstrate.
IBM describes human-in-the-loop systems as most valuable “when high stakes exist, ethical judgment is required, or regulatory compliance demands it.” SOC 2 evidence collection checks all three. A screenshot from your staging environment instead of production isn’t just wrong. It’s an audit finding. An attestation letter with the wrong date range creates a control gap. These are judgment failures that automation alone won’t catch.
So full automation handles the easy stuff. And the easy stuff might be the majority of items. But the remaining items, the ones that need human evaluation, are often the ones auditors scrutinize most carefully.
The three-phase guided workflow
What we built isn’t an automation system. It’s a guided workflow where AI manages the session state and a human makes decisions.
Phase one is setup. The AI agent parses the evidence inventory file, loads the audit progress tracker to figure out where the last session left off, and reads the control-to-evidence mappings for context. This takes seconds. But it means you can stop a session midway through 37 items and pick up exactly where you left off tomorrow. Session resumption sounds trivial until you’ve lost track of which items you already collected and which ones still need attention.
Phase two is the per-item loop. This is where most of the time goes. For each evidence item due for collection, the AI presents the item details: what system it comes from, what type of evidence it is, what the previous year’s evidence looked like. That last part matters more than you’d expect. Seeing last year’s screenshot of a password policy page tells you exactly where to look this year and what’s changed. The human then collects the new evidence, and the AI runs visual verification to check that the screenshot or export matches what was expected.
Phase three is session wrap-up. The AI generates a summary with completion statistics. How many items collected this session. How many remain. What percentage of the full inventory is complete. Which items are overdue. This tracking data itself becomes evidence that you have a functioning compliance program. If you want to go deeper on how we replaced our compliance platform entirely, the organizational structure is covered there.
The three-phase approach means every session starts clean, runs through a defined loop, and ends with a clear state.
How each evidence session actually runs
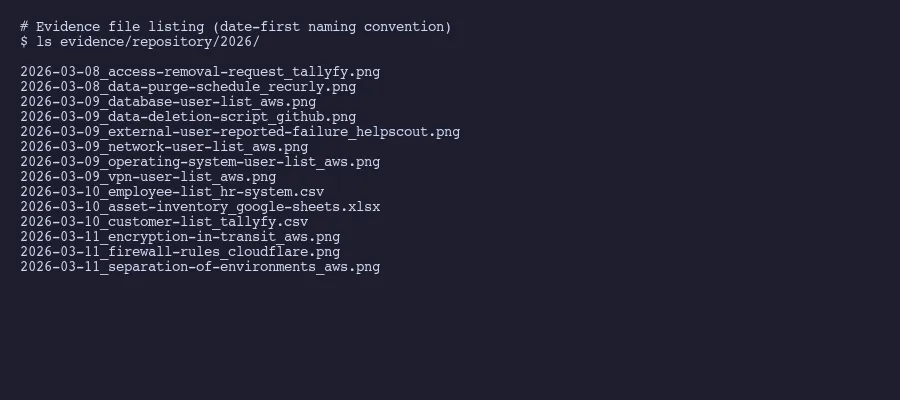
Our March 2026 collection illustrates the acceleration pattern. Session one on March 8th captured 2 items. Session two on March 9th hit 24. Session three on March 10th pushed through 37. And session four on March 11th finished with 36. Total: 99 of 123 items, with 24 not yet due based on their collection frequency.
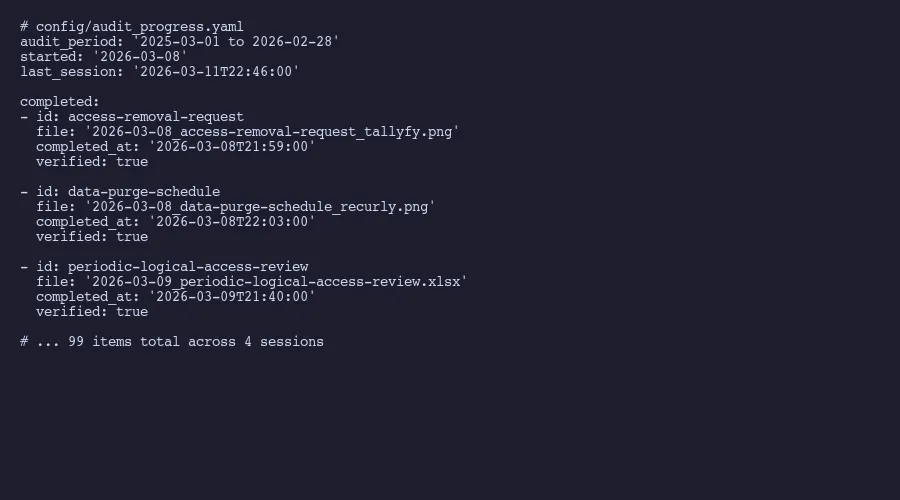
The first session is slow because calibration takes time. The AI and the human are getting synchronized. Which browser tabs need to be open. What the naming convention requires. How to handle items that have changed since last year. By session two, the rhythm is established.
Here’s what actually happens during a typical item in the loop.
The AI says: “Next item is database-user-list. Source is AWS IAM. Evidence type is population export. Last year’s evidence was collected on 2025-03-12 and showed 14 users.” You go to AWS, pull the current user list, and hand it to the agent. The AI checks: is this from the production account and not staging? Does the date fall within the current audit period? Does the user count seem reasonable compared to last year’s 14? If anything looks off, it flags the issue before the file gets saved.

That visual verification step catches real problems. Staging-versus-production mix-ups happen more often than anyone admits. Wrong date ranges slip through when you’re moving fast. If you’re trying to understand what your auditor needs from your AI tooling, evidence quality is exactly the kind of thing that separates a clean audit from a findings list.
Screenshots get verified for system identity and date visibility. Exports get checked for expected column structure and reasonable row counts. Attestation letters get verified for correct item references and appropriate date ranges.
Attestation letters and vendor reviews
Two evidence categories deserve special attention because they’re the ones full automation completely misses.
Attestation letters exist for items that genuinely don’t apply to your organization. Maybe you don’t process payment card data, so PCI-related controls are not applicable. Maybe you don’t operate physical data centers, so physical security controls are handled by your cloud provider. Each of these needs a formal letter, not a note in a spreadsheet, explaining why the control doesn’t apply.
The letter follows a simple structure. Date. Reference to the specific evidence item by ID. A statement that the item is not applicable. The specific reason why. A signature from someone authorized to make that determination.
The AI generates the letter from a template. But the human has to verify the reasoning. “We don’t process payment cards” is straightforward. “This control is covered by our cloud provider’s SOC 2 report” requires actually checking that the provider’s report covers the relevant criteria. That’s a judgment call. The AI can pull up the provider’s report and highlight the relevant sections. The human decides whether the coverage is sufficient.
Vendor reviews follow a similar pattern. When a vendor provides their own SOC 2 report, you need to assess whether it covers the services you use from them and whether their control descriptions map to your requirements. When a vendor doesn’t have a SOC 2 report, you review whatever compliance documentation they do publish. Cloud provider trust centers, security whitepapers, published certifications. The EU AI Act’s human oversight requirements for high-risk systems reflect a broader pattern: regulatory frameworks increasingly recognize that automated review isn’t sufficient for decisions with real consequences.
The AI organizes the vendor list, pulls their publicly available compliance documentation links, and presents them systematically. The human reads the material and records a judgment: does this vendor’s compliance posture meet our requirements? That binary determination can’t be automated without accepting risk that no reasonable auditor would accept.
What AI is genuinely good at in evidence collection
Strip away the vendor marketing and the honest answer is: AI excels at workflow orchestration, not decision-making. If you want help figuring this kind of thing out for your company, I’m happy to talk.
Session state management is where it shines brightest. Tracking 123 items across four frequency tiers, remembering which ones are collected, calculating next-due dates, picking up exactly where you left off. A human doing this manually needs a spreadsheet, constant context-switching, and the discipline to update tracking data after every single item. The AI just does it.
Presentation of context is equally valuable. Showing last year’s evidence alongside this year’s collection request gives the human instant orientation. The comparison reveals what changed. New users appeared in the access list. A configuration setting moved from one page to another. The policy version number incremented. Without that context, the human is working from memory or searching through last year’s files.
Verification catches mechanical errors. Not judgment errors. The AI won’t tell you whether a vendor’s SOC 2 report adequately covers your risk. But it will tell you that your screenshot shows a staging URL instead of production. It will flag that your export file has 3 rows when last year’s had 47, which probably means something went wrong with the export filter. It will notice that the date in your attestation letter doesn’t match the current audit period.
Naming and filing is pure automation territory. Every file named according to the convention. Every item tracked with collection date and next-due date. Every session summarized with completion statistics. This is the work that a practitioner accounts of SOC 2 preparation shows companies spending months on when done manually.
What the AI explicitly does not do: sign attestation letters, evaluate vendor compliance posture, decide whether a control applies, determine if evidence is sufficient, or make any call that an auditor would later question. Those stay with the human. That boundary is the whole point.
The chess grandmaster Garry Kasparov found this out decades ago. After losing to Deep Blue, he helped pioneer “advanced chess” where human-machine pairs compete. HBR reported on his key insight: “Weak human + machine + better process was superior to a strong computer alone.” Replace “chess” with “evidence collection” and the principle holds. A defined process where AI handles orchestration and humans handle judgment produces better results than either one working alone.
Four sessions. Four days. Ninety-nine items. And the items that didn’t get collected weren’t missed. They weren’t due yet. The process knows the difference, which is more than most people managing this manually can say about their spreadsheets.
About the Author
Amit Kothari is an experienced consultant, advisor, coach, and educator specializing in AI and operations for executives and their companies. With 25+ years of experience and as the founder of Tallyfy (raised $3.6m), he helps mid-size companies identify, plan, and implement practical AI solutions that actually work. Originally British and now based in St. Louis, MO, Amit combines deep technical expertise with real-world business understanding.
Disclaimer: The content in this article represents personal opinions based on extensive research and practical experience. While every effort has been made to ensure accuracy through data analysis and source verification, this should not be considered professional advice. Always consult with qualified professionals for decisions specific to your situation.